El sistema operativo administra la distribución del procesador entre los distintos programas por medio de un algoritmo de programación. El tipo de programador depende completamente del sistema operativo, según el objetivo deseado.

3.1 PLANEACIÓN DE TRABAJOS DE (JOB SCHEDULING)
Cuando hay más de un proceso que está en condiciones de ejecutarse en la CPU, se debe escoger alguno. El encargado de tomar esa decisión es el planificador o scheduler, y el algoritmo que usa se llama algoritmo de planificación. (Scheduler = planificación).
Los objetivos de esta planificación son:
Justicia: Asegurarse que todos los procesos tengan su turno de CPU.
 Eficiencia: Mantener la CPU ocupada todo el tiempo.
Eficiencia: Mantener la CPU ocupada todo el tiempo.Tiempo de respuesta: Minimizar el tiempo de respuesta de los usuarios interactivos.
Rendimiento o productividad (throughput): Maximizar el número de trabajos terminados por hora.
Tiempo de espera: Minimizar el tiempo medio de espera (en la cola READY) de los procesos.
Hay un gran número de fases de CPU cortos, y muy pocos largos. Esta información puede ser importante para seleccionar un algoritmo de planificación adecuado. Una decisión de planificación puede o debe tomarse cuando ocurre cualquiera de las siguientes transiciones entre estados de un proceso:
Hay un gran número de fases de CPU cortos, y muy pocos largos. Esta información puede ser importante para seleccionar un algoritmo de planificación adecuado. Una decisión de planificación puede o debe tomarse cuando ocurre cualquiera de las siguientes transiciones entre estados de un proceso:
* EJECUTANDO a BLOQUEADO.
* EJECUTANDO a TERMINADO.
* EJECUTANDO a LISTO.
* BLOQUEADO a LISTO.
En los casos 1 y 2, necesariamente hay que escoger un nuevo proceso, pero en los casos 3 y 4 podría no tomarse ninguna decisión de scheduling, y dejar que continúe ejecutando el mismo proceso que estaba en ejecución ya casi listo.
3.2 CONCEPTOS BÁSICOS DE JOB SHEDULING
 Una de las principales funciones es maximizar la utilización del CPU obtenida con la multiprogramación.
Una de las principales funciones es maximizar la utilización del CPU obtenida con la multiprogramación.Y algunos de los conceptos principales o básicos dentro de la planeación de trabajos Job Scheduling son los siguientes:
PLANIFICADOR DE TAREAS: Es una aplicación de software de la empresa que se encarga de las ejecuciones desatendida fondo, comúnmente conocido por razones históricas como del procesamiento por lotes.
PROCESAMIENTO POR LOTE: (Lote sistema, Sistema de Gestión de Recursos Distribuidos (SGDD), y Distributed Resource Manager (DRM)).
Hoy en día los programadores están obligados a organizar la integración de los negocios en tiempo real con las actividades tradicionales de transformación de fondo que, a través de diferentes plataformas de sistemas operativos y entornos de aplicaciones de negocio.
Más allá de la básica, herramienta de programación única instancia de SO hay dos arquitecturas principales que existen para el software de planificación de trabajo.
Maestro / Agente de la arquitectura - El software Job Scheduling se instala en una sola máquina (Master), mientras que en equipos de producción sólo un componente muy pequeño (agente) está instalado que le espera a las órdenes del Maestro, los ejecuta, y devuelve el código de salida de nuevo al Maestro.
Arquitectura Cooperativa - Esto permite equilibrar la carga de trabajo dinámico para maximizar la utilización de los recursos de hardware y de alta disponibilidad para garantizar la prestación de servicios.
3.3. TIPOS DE PLANEACION JOB SCHEDULING
Objetivo de la planificación: Minimizar el tiempo de espera y minimizar el tiempo de respuesta. La planificación (scheduling) es la base para lograr la multiprogramación. Un sistema multiprogramado tendrá varios procesos que requerirán el recurso procesador a la vez.

Esto sucede cuando los procesos están en estado ready (pronto). Si existe un procesador disponible, se debe elegir el proceso que será asignado para ejecutar. La parte del sistema operativo que realiza la elección del proceso es llamada planificador (scheduler). La planificación hace referencia a un conjunto de políticas Y mecanismos incorporados a sistemas operativos que gobiernan el orden en que se ejecutan los trabajos.
Un planificador es un módulo del S.O que selecciona el siguiente trabajo que hay que admitir en el sistema y el siguiente proceso que hay que ejecutar. En muchos sistemas, la actividad de planificación se divide en tres funciones independientes: planificación a largo, medio, y corto plazo.
3.3.1 FIRST IN FIRST OUT (FIFO)
First in, first out o FIFO (en español "primero en entrar, primero en salir"), es un concepto utilizado en estructuras de datos, contabilidad de costes y teoría de colas. Guarda analogía con las personas que esperan en una cola y van siendo atendidas en el orden en que llegaron, es decir, que la primera persona que entra es la primera persona que sale.
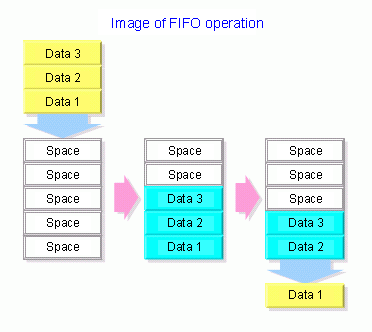 También se lo llama first come first served o FCFS (en español "primero en llegar, primero en ser atendido").
También se lo llama first come first served o FCFS (en español "primero en llegar, primero en ser atendido").FIFO se utiliza en estructuras de datos para implementar colas. La implementación puede efectuarse con ayuda de arrays o vectores, o bien mediante el uso de punteros y asignación dinámica de memoria.
La CPU se asigna a los procesos en el orden que lo solicitan, cuando el primer proceso entra en el sistema, se le inicia de inmediato y se le permite ejecutar todo el tiempo que necesite, cuando llegan otros procesos se les coloca al final de la cola. Cuando se bloquea el proceso en ejecucion, se ejecuta el primer proceso de la cola, si un proceso bloqueado vuelve a estar listo se le coloca al final de la cola como si fuera un proceso recién llegado.
3.3.2 ROUND ROBIN (RR)
 Round robin es un método para seleccionar todos los elementos en un grupo de manera equitativa y en un orden racional, normalmente comenzando por el primer elemento de la lista hasta llegar al último y empezando de nuevo desde el primer elemento. El nombre del algoritmo viene del principio de Round-Roubin conocido de otros campos, donde cada persona toma una parte de un algo compartido en cantidades parejas.
Round robin es un método para seleccionar todos los elementos en un grupo de manera equitativa y en un orden racional, normalmente comenzando por el primer elemento de la lista hasta llegar al último y empezando de nuevo desde el primer elemento. El nombre del algoritmo viene del principio de Round-Roubin conocido de otros campos, donde cada persona toma una parte de un algo compartido en cantidades parejas.Algoritmo apropiativo consistente en determinar un quantum (tiempo de reloj) que marcará el intervalo de CPU que se le cederá al proceso ejecutando. Cuando finalice el quantum al proceso se le quitará la CPU y pasará a la cola de listo. La cola de listos sigue la estructura FIFO. Si un proceso no consume su quantum libera la CPU y ésta es asignada al siguiente proceso de la cola de listo.
Los procesos se despachan en “FIFO” y disponen de una cantidad limitada de tiempo de cpu, llamada “división de tiempo” o “cuanto”.
3.3.3 SHORTEST JOB FIRST (SJF)
Es una disciplina no apropiativa y por lo tanto no recomendable en ambientes de tiempo compartido. El proceso en espera con el menor tiempo estimado de ejecución hasta su terminación es el siguiente en ejecutarse. Los tiempos promedio de espera son menores y menos predecibles que con “FIFO”.
 Favorece a los procesos cortos en detrimento de los largos y tiende a reducir el número de procesos en espera y el número de procesos que esperan detrás de procesos largos. Requiere un conocimiento preciso del tiempo de ejecución de un proceso, lo que generalmente se desconoce. Se pueden estimar los tiempos en base a series de valores anteriores.
Favorece a los procesos cortos en detrimento de los largos y tiende a reducir el número de procesos en espera y el número de procesos que esperan detrás de procesos largos. Requiere un conocimiento preciso del tiempo de ejecución de un proceso, lo que generalmente se desconoce. Se pueden estimar los tiempos en base a series de valores anteriores.El algoritmo asocia a los procesos el largo de su próximo CPU-burst. Cuando el procesador queda disponible se le asigna al proceso que tenga el menor CPU-burst. Si dos procesos tiene el mismo CPU-burst se desempata de alguna forma. Su funcionamiento depende de conocer los tiempos de ejecución, que en la mayoría de los casos no se conoce. Es adecuado para sistemas por lotes (batch).
3.3.4 SHORTEST REMAINING TIME (STR)
Esta disciplina elige siempre al proceso que le queda menos tiempo de ejecución estimado para completar su ejecución; de esta forma aunque un proceso requiera mucho tiempo de ejecución, a medida que se va ejecutando iría avanzando en la lista de procesos en estado listo hasta llegar a ser el primero. Para realizar esta elección, es necesario actualizar el PCB de los procesos a medida que se le asigna tiempo de servicio, lo que supone una mayor sobrecarga adicional.

Es una disciplina apropiativa ya que a un proceso activo se le puede retirar la CPU si llega a la lista de procesos en estado listo otro con un tiempo restante de ejecución estimado menor. Este algoritmo es la versión no apropiativa o espulsiva del algoritmo Shortest Process Next (SPN) o también llamado Shortest Job First (SJF).
En este algoritmo el planificador selecciona el proceso más corto, al igual que antes, pero en este caso el cambio se controla cada vez que un proceso llega a la cola. Es decir, cuando un proceso se desbloquea o se crea uno nuevo y el tiempo de ráfaga es menor que el tiempo de ráfaga del proceso que se está ejecutando, entonces se realiza un cambio de contexto, el bloqueado se ejecuta y el que se estaba ejecutando pasa a la cola de procesos listos. De este modo cuando se desbloquea o entra un proceso nuevo, se calcula su tiempo de ráfaga. Si el proceso que se está ejecutando le queda más tiempo de ráfaga que nuestro tiempo de ráfaga calculado entonces se procede a realizar el cambio de contexto.
3.3.5 HIGHEST RESPONSE RATIO NEXT (HNR)
Highest Response Ratio Next: (El de mayor tasa de respuesta el próximo). Algoritmo apropiativo parecido al SRT consistente en calcular el Reponse Ratio (Ratio de respuesta) para asignar la CPU a procesos más viejos.
 Para cada proceso, basado en el tiempo que va a ocupar el procesador(s) y el tiempo que lleva esperando para ocuparlo (w), se calcula w+s/s, una vez hecho esto el proceso que tenga un valor mayor será asignado al procesador. Este algoritmo es bastante bueno, porque además de dar preferencia a los procesos cortos también tiene en cuenta el envejecimiento de los procesos para evitar así la "inanición".
Para cada proceso, basado en el tiempo que va a ocupar el procesador(s) y el tiempo que lleva esperando para ocuparlo (w), se calcula w+s/s, una vez hecho esto el proceso que tenga un valor mayor será asignado al procesador. Este algoritmo es bastante bueno, porque además de dar preferencia a los procesos cortos también tiene en cuenta el envejecimiento de los procesos para evitar así la "inanición".Es muy productivo pero se sobrecarga el sistema, además ofrece un buen tiempo de respuesta, equilibra los procesos, aunque da prioridad a los procesos más cortos y evita la inanición (los procesos que envejecen serán ejecutados). Las prioridades, que son dinámicas, se calculan según la siguiente fórmula, donde pr es la “prioridad”, te es el “tiempo de espera” y ts es el “tiempo de servicio”.
3.4 MULTIPROCESAMIENTO
Es tradicionalmente conocido como el uso de múltiples procesos concurrentes en un sistema en lugar de un único proceso en un instante determinado. Como la multitarea que permite a múltiples procesos compartir una única CPU, múltiples CPUs pueden ser utilizados para ejecutar múltiples hilos dentro de un único proceso.

Un multiprocesador se define como una computadora que contiene dos o más unidades de procesamiento que trabajan sobre una memoria común bajo un control integrado. Si el sistema de multiprocesamiento posee procesadores de aproximadamente igual capacidad, estamos en presencia de multiprocesamiento simétrico; en el otro caso hablamos de multiprocesamiento asimétrico.
Si un procesador falla, los restantes continúan operando, lo cual no es automático y requiere de un diseño cuidadoso. Un procesador que falla habrá de informarlo a los demás de alguna manera, para que se hagan cargo de su trabajo. Los procesadores en funcionamiento deben poder detectar el fallo de un procesador.
El multiproceso para tareas generales es, a menudo, bastante difícil de conseguir debido a que puede haber varios programas manejando datos internos (conocido como estado o contexto) a la vez. Los programas típicamente se escriben asumiendo que sus datos son incorruptibles. Sin embargo, si otra copia del programa se ejecuta en otro procesador, las dos copias pueden interferir entre sí intentando ambas leer o escribir su estado al mismo tiempo.
Para evitar este problema se usa una variedad de técnicas de programación incluyendo semáforos y otras comprobaciones y bloqueos que permiten a una sola copia del programa cambiar de forma exclusiva ciertos valores.
3.5 CONCEPTOS BASICOS DE MULTIPROCESADOR
MULTIPROCESADOR: Se denomina multiprocesador a un computador que cuenta con dos o más microprocesadores (CPUs).Gracias a esto, el multiprocesador puede ejecutar simultáneamente varios hilos pertenecientes a un mismo proceso o bien a procesos diferentes.
EXTENSION DE MULTIPROCESADORES: Son aquellos sistemas operativos que están montados sobre ordenadores que están compuestos por más de un procesador.Dos factores clave para la extensión de los Multiprocesadores son:
Flexibilidad: El mismo sistema puede usarse para un único usuario incrementado el rendimiento en la ejecución de una única aplicación o para varios usuarios y aplicaciones en un entorno compartido.
Coste-rendimiento: Actualmente estos sistemas se basan en procesadores comerciales, por lo que su coste se ha reducido drásticamente. La inversión más fuerte se hace en la memoria y la red de interconexión.
CLASIFICACION POR USO DE LOS RECURSOS
Sistemas monoprogramados: Son los que solo permiten la ejecución de un programa en el sistema, se instalan en la memoria y permanecen allí hasta que termine su ejecución.
Sistemas multiprogramados: Son aquellos que se basan en las técnicas de multiprogramación, existen dos tipos:
· Multitarea apropiativa (preemptive): Se utiliza en sistemas operativos cuya gestión es quitar el control del microprocesador al programa que lo tiene.
· Multitarea cooperativa: El programa tiene el control del microprocesador, el sistema operativo no puede decidir quien usa el microprocesador.

· Procesamiento por lotes (batch): Cada programa realiza un conjunto de pasos secuenciales relacionados entre si.
Los sistemas de ordenador de multiprocesador son caros y encontraron su uso sólo en la aplicación de informática compleja y en la alta velocidad que funda el punto aplicación de cálculo numérica en espacios de Investigación e Industria.
3.6 PARALELISMO MULTIPROCESAMIENTO
El paralelismo consiste en ejecutar más instrucciones en menos tiempo, aunque las instrucciones sigan tardando lo mismo en ejecutarse. Los multiprocesadores hacen posible la explotación del paralelismo.

Los sistemas de computación obtienen los beneficios del procesamiento concurrente más por la “multiprogramación” de varios procesos y menos por la explotación del “paralelismo” dentro de un solo proceso. La detección del paralelismo es un problema complejo y la puede efectuar el programador, el traductor del lenguaje, el hardware o el Sistema Operativo. El paralelismo dentro de los programas puede ser “explícito” o “implícito”.
3.7 SISTEMAS MULTIPROCESAMIENTO
La técnica de multiprocesamiento consiste en hacer funcionar varios procesadores en forma paralela para obtener un poder de cálculo mayor que el obtenido al usar un procesador de alta tecnología o al aumentar la disponibilidad del sistema (en el caso de fallas del procesador).
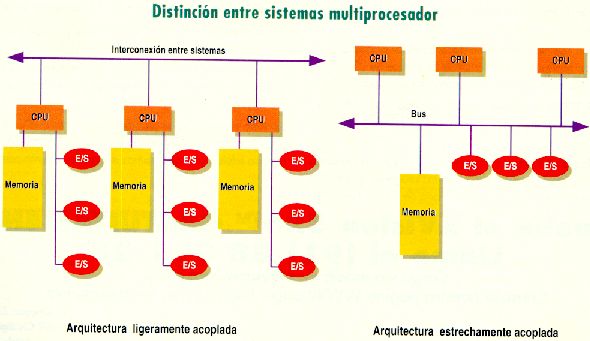
· Multiprocesamiento simétrico: Cada procesador ejecuta una copia del sistema operativo.
· Multiprocesamiento asimétrico: Cada procesador tiene asignado una tarea específica, existe un procesador master que asigna tareas a los procesadores esclavos.
Las computadoras que tienen más de un CPU son llamadas multiproceso y un sistema operativo multiproceso coordina las operaciones de las computadoras multiprocesadores, ya que cada CPU en una computadora de multiproceso puede estar ejecutando una instrucción, el otro procesador queda liberado para procesar otras instrucciones simultáneamente.
Al usar una computadora con capacidades de multiproceso incrementamos su velocidad de respuesta y procesos. Casi todas las computadoras que tienen capacidad de multiproceso ofrecen una gran ventaja.
3.8 ORGANIZACIÓN DEL MULTIPROCESADOR
Los multiprocesadores se caracterizan por los siguientes aspectos:
ü Un multiprocesador contiene dos o más procesadores con capacidades aproximadamente comparables.
ü Todos los procesadores comparten el acceso a un almacenamiento común y a canales de Entrada / Salida, unidades de control y dispositivos.
ü Todo está controlado por un Sistema Operativo que proporciona interacción entre procesadores y sus programas en los niveles de trabajo, tarea, paso, archivo y elementos de datos.
Las organizaciones más comunes son las siguientes:
Tiempo compartido o bus común (conductor común): Usa un solo camino de comunicación entre todas las unidades funcionales. El bus común es en esencia una unidad pasiva.
Un procesador o procesador de Entrada / Salida que desee transferir datos debe efectuar los siguientes pasos:
1. Verificar la disponibilidad del conductor y de la unidad de destino.
2. Informar a la unidad de destino de lo que se va a hacer con los datos.
3. Iniciar la transferencia de datos.
4. Las unidades receptoras deben poder reconocer qué mensajes del bus son enviados hacia ellas y seguir y confirmar las señales de control recibidas de la unidad emisora.

Almacenamiento de interconexión múltiple: Se obtiene al sacar las lógicas de control, de conmutación y de arbitraje de prioridades fuera del interruptor de barras cruzadas y se las coloca en la interfaz de cada unidad de almacenamiento.
Cada unidad funcional puede acceder a cada unidad de almacenamiento, pero sólo en una “conexión de almacenamiento” específica, es decir que hay una conexión de almacenamiento por unidad funcional.
El conexionado es más complejo que en los otros esquemas. Se puede restringir el acceso a las unidades de almacenamiento para que no todas las unidades de procesamiento las accedan, en tal caso habrá unidades de almacenamiento “privadas” de determinados procesadores.
3.9 SISTEMAS OPERATIVOS DEL MULTIPROCESADOR
Para que un multiprocesador opere correctamente necesita un sistema operativo especialmente diseñado para ello.

La mayoría de los sistemas operativos actuales poseen esta capacidad. Las capacidades funcionales de los Sistemas Operativos de multiprogramación y de multiprocesadores incluyen lo siguiente:
• Asignación y administración de recursos.
• Protección de tablas y conjuntos de datos.
• Prevención contra el interbloqueo del sistema.
• Terminación anormal.
• Equilibrio de cargas de Entrada / Salida.
• Equilibrio de carga del procesador.
• Reconfiguración.
Las tres últimas son especialmente importantes en Sistemas Operativos de multiprocesadores, donde es fundamental explotar el paralelismo en el hardware y en los programas y hacerlo automáticamente.
Las organizaciones básicas de los Sistemas Operativos para multiprocesadores son las siguientes:
Maestro / satélite: Es la organización más fácil de implementar. No logra la utilización óptima del hardware dado que sólo el procesador maestro puede ejecutar el Sistema Operativo y el procesador satélite sólo puede ejecutar programas del usuario.
Ejecutivo separado para cada procesador: Cada procesador tiene su propio Sistema Operativo y responde a interrupciones de los usuarios que operan en ese procesador.
La mayoría de los sistemas operativos actuales poseen esta capacidad. Las capacidades funcionales de los Sistemas Operativos de multiprogramación y de multiprocesadores incluyen lo siguiente:
• Asignación y administración de recursos.
• Protección de tablas y conjuntos de datos.
• Prevención contra el interbloqueo del sistema.
• Terminación anormal.
• Equilibrio de cargas de Entrada / Salida.
• Equilibrio de carga del procesador.
• Reconfiguración.
Las tres últimas son especialmente importantes en Sistemas Operativos de multiprocesadores, donde es fundamental explotar el paralelismo en el hardware y en los programas y hacerlo automáticamente.
Las organizaciones básicas de los Sistemas Operativos para multiprocesadores son las siguientes:
Maestro / satélite: Es la organización más fácil de implementar. No logra la utilización óptima del hardware dado que sólo el procesador maestro puede ejecutar el Sistema Operativo y el procesador satélite sólo puede ejecutar programas del usuario.
Ejecutivo separado para cada procesador: Cada procesador tiene su propio Sistema Operativo y responde a interrupciones de los usuarios que operan en ese procesador.
Existen tablas de control con información global de todo el sistema (por ejemplo, lista de procesadores conocidos por el Sistema Operativo) a las que se debe acceder utilizando exclusión mutua.
Tratamiento simétrico (o anónimo) para todos los procesadores: Es la organización más complicada de implementar y también la más poderosa y confiable. El Sistema Operativo administra un grupo de procesadores idénticos, donde cualquiera puede utilizar cualquier dispositivo de Entrada / Salida y cualquiera puede referenciar a cualquier unidad de almacenamiento.
El procesador ejecutivo es el responsable (uno sólo) en un momento dado de las tablas y funciones del sistema; así se evitan los conflictos sobre la información global.
El procesador ejecutivo es el responsable (uno sólo) en un momento dado de las tablas y funciones del sistema; así se evitan los conflictos sobre la información global.





























{kind=link}